
1. 前言
在大学期间学Java Web的时候,当JSP不涉及中文的时候,没有一点问题,可是一旦涉及中文,就经常出现乱码,这时候就需要进行转码。需要将字符集设置为GB2312、UTF-8或者ISO-8859-1,但当时并不清楚这些编码之间有什么区别,只是在出现乱码后,在网络上查询相关解决办法,然后一个个try一下。而字符显示正常后,就并不去管了(汗。。。)。
现在有闲暇,便对字符编码进行了研究,并进行一个小结。本篇小结主要分为:字符集与字符编码、字符编码分类以及不同编码之间的区别。
2. 字符集与字符编码
字符是各种文字和符号的总称,包括各个国家文字、标点符号、图形符号和数字等。使用哪些字符。也就是说哪些汉字,字母和符号会被收入标准中。所包含“字符”的集合就叫做“字符集”。,字符集种类较多,每个字符集包含的字符个数不同,常见字符集有:ASCII字符集、ISO 8859字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。字符编码就是以二进制的数字来对应字符集的字符。字符编码(英语:Character encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。
3. 字符编码的分类
简单介绍一下常用的编码规则,为后边的章节做一个准备。在这里,我们根据编码规则的特点,把所有的编码分成三类:
| 阶段 | 系统内码 | 说明 | 系统 |
|---|---|---|---|
| 阶段一 | ASCII | 计算机刚开始只支持英语,其它语言不能够在计算机上存储和显示。 | 英文 DOS |
| 阶段二 | ANSI编码(本地化) | 为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。 | 中文 DOS,中文 Windows 95/98,日文 Windows 95/98 |
| 阶段三 | UNICODE(国际化) | 为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。 | Windows NT/2000/XP,Linux,Java |
3.1 ASCII编码
ASCII(American Standard Code for Information Interchange),美国国家信息交换标准代码,一种使用7个或8个二进制位进行编码的方案,最多可以给256个字符(包括字母、数字、标点符号、控制字符以及其他符号)分配(或指定)数值。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统(但是有被UniCode追上的迹象),并等同于国际标准ISO/IEC 646。
基本的 ASCII 字符集共有 128 个字符,其中有 96 个可打印字符,包括常用的字母、数字、标点符号等,另外还有 32 个控制字符。标准 ASCII 码使用 7 个二进位对字符进行编码。其ASCII码的表格如下: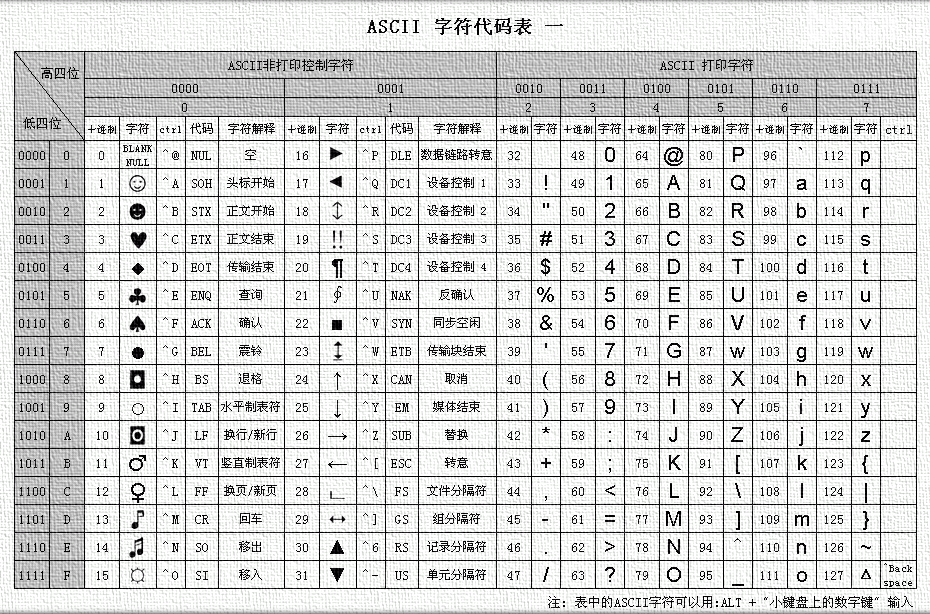
常见的ASCII码主要有:换行->10,回车->13,0->48,A->65,a->97。虽然标准 ASCII 码是 7 位编码,但由于计算机基本处理单位为字节( 1byte = 8bit ),所以一般仍以一个字节来存放一个 ASCII 字符。每一个字节中多余出来的一位(最高位)在计算机内部通常保持为 0 (在数据传输时可用作奇偶校验位)。
ASCII缺点:
ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如naïve、café、élite等等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)。而EASCII虽然解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。因此现在的苹果电脑已经抛弃ASCII而转用Unicode。
3.2 ANSI编码
为使计算机支持更多语言,通常使用0x800~xFF范围的2个字节来表示1个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0]这两个字节存储。
不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为ANSI 编码。在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。
3.3 GB2312编码
GB2312 也是ANSI编码里的一种,对ANSI编码最初始的ASCII编码进行扩充,为了满足国内在计算机中使用汉字的需要,中国国家标准总局发布了一系列的汉字字符集国家标准编码,统称为GB码,或国标码。其中最有影响的是于1980年发布的《信息交换用汉字编码字符集 基本集》,标准号为GB 2312-1980,因其使用非常普遍,也常被通称为国标码。
GB2312 是一个简体中文字符集,由由6763个常用汉字和682个全角的非汉字字符组成。其中汉字根据使用的频率分为两级。一级汉字3755个,二级汉字3008个。由于字符数量比较大,GB2312采用了二维矩阵编码法对所有字符进行编码。首先构造一个94行94列的方阵,对每一行称为一个“区”,每一列称为一个“位”,然后将所有字符依照下表的规律填写到方阵中。这样所有的字符在方阵中都有一个唯一的位置,这个位置可以用区号、位号合成表示,称为字符的区位码。如第一个汉字“啊”出现在第16区的第1位上,其区位码为1601。因为区位码同字符的位置是完全对应的,因此区位码同字符之间也是一一对应的。这样所有的字符都可通过其区位码转换为数字编码信息。GB2312字符的排列分布情况见下图。
GB2312字符在计算机中存储是以其区位码为基础的,其中汉字的区码和位码分别占一个存储单元,每个汉字占两个存储单元。由于区码和位码的取值范围都是在1-94之间,这样的范围同西文的存储表示冲突。为避免同西文的存储发生冲突,GB2312字符在进行存储时,通过将原来的每个字节第8bit设置为1同西文加以区别,如果第8bit为0,则表示西文字符,否则表示GB2312中的字符。实际存储时,采用了将区位码的每个字节分别加上A0H(160)的方法转换为存储码,计算机存储规则是此编码的补码,而且是位码在前,区码在后。例如汉字‘啊’的区位码为1601,其存储码为B0A1H。GB2312编码用两个字节(8位2进制)表示一个汉字,所以理论上最多可以表示256×256=65536个汉字。但这种编码方式也仅仅在中国行得通,如果您的网页使用的GB2312编码,那么很多外国人在浏览你的网页时就可能无法正常显示,因为其浏览器不支持GB2312编码。当然,中国人在浏览外国网页(比如日文)时,也会出现乱码或无法打开的情况,因为我们的浏览器没有安装日文的编码表。
3.4 GBK编码
GBK(国标扩展码)编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。GB2312码是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集——基本集》,1980年由国家标准总局发布。
GB 2312的出现,基本满足了汉字的计算机处理需要,但对于人名、古汉语等方面出现的罕用字,GB 2312不能处理,这导致了后来GBK及GB 18030汉字字符集的出现。
编码方式:字符有一字节和双字节编码,00–7F范围内是一位,和ASCII保持一致,此范围内严格上说有96个字符和32个控制符号。之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。
3.5 Unicode编码
当我们使用ANSI编码方式的时候,对应于同一个二进制编码值进行显示的时候,如果我们采用不同的编码,就可能导致乱码。这就促使了Unicode码的诞生。Unicode码将世界上所有的符号都纳入其中,无论是英文、日文还是中文,大家都使用这个编码表,就不会出现编码不匹配的现象。每个符号对应唯一一个编码,乱码问题就不存在了。这就是Unicode编码。
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
Unicode固然统一了编码方式,但是它的效率不高,比如UCS-4(Unicode的标准之一)规定用4个字节存储一个符号,那么每个英文字母前都必然有三个字节是0,这对存储和传输来说都很耗资源。
3.6 UTF-8编码
为了提高Unicode的编码效率,于是就出现了UTF-8(8-bit Unicode Transformation Format)编码。UTF-8可以根据不同的符号自动选择编码的长短。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
事实证明,对可以用ASCII表示的字符使用UNICODE并不高效,因为UNICODE比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Universal Transformation Format)。常见的UTF格式有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。
优点
UTF-8编码可以通过屏蔽位和移位操作快速读写。字符串比较时strcmp()和wcscmp()的返回结果相同,因此使排序变得更加容易。字节FF和FE在UTF-8编码中永远不会出现,因此他们可以用来表明UTF-16或UTF-32文本(见BOM) UTF-8 是字节顺序无关的。它的字节顺序在所有系统中都是一样的,因此它实际上并不需要BOM。
缺点
你无法从UNICODE字符数判断出UTF-8文本的字节数,因为UTF-8是一种变长编码它需要用2个字节编码那些用扩展ASCII字符集只需1个字节的字符 ISO Latin-1 是UNICODE的子集,但不是UTF-8的子集 8位字符的UTF-8编码会被email网关过滤,因为internet信息最初设计为7位ASCII码。因此产生了UTF-7编码。 UTF-8 在它的表示中使用值100xxxxx的几率超过50%, 而现存的实现如ISO 2022, 4873, 6429, 和8859系统,会把它错认为是C1 控制码。因此产生了UTF-7.5编码。
4. 对编码的误解
- 在将“字节串”转化成“UNICODE 字符串”时,比如在读取文本文件时,或者通过网络传输文本时,容易将“字节串”简单地作为单字节字符串,采用每“一个字节”就是“一个字符”的方法进行转化。而实际上,在非英文的环境中,应该将“字节串”作为 ANSI 字符串,采用适当的编码来得到 UNICODE 字符串,有可能“多个字节”才能得到“一个字符”。通常,一直在英文环境下做开发的程序员们,容易有这种误解。
- 在 DOS,Windows 98 等非 UNICODE 环境下,字符串都是以 ANSI 编码的字节形式存在的。这种以字节形式存在的字符串,必须知道是哪种编码才能被正确地使用。这使我们形成了一个惯性思维:“字符串的编码”。当 UNICODE 被支持后,Java 中的 String 是以字符的“序号”来存储的,不是以“某种编码的字节”来存储的,因此已经不存在“字符串的编码”这个概念了。只有在“字符串”与“字节串”转化时,或者,将一个“字节串”当成一个 ANSI 字符串时,才有编码的概念。不少的人都有这个误解。
5. 乱码的产生
5.1 非 UNICODE 程序在不同语言环境间移植时的乱码
非 UNICODE 程序中的字符串,都是以某种 ANSI 编码形式存在的。如果程序运行时的语言环境与开发时的语言环境不同,将会导致 ANSI 字符串的显示失败。比如,在日文环境下开发的非 UNICODE 的日文程序界面,拿到中文环境下运行时,界面上将显示乱码。如果这个日文程序界面改为采用 UNICODE 来记录字符串,那么当在中文环境下运行时,界面上将可以显示正常的日文。由于客观原因,有时候我们必须在中文操作系统下运行非 UNICODE 的日文软件,这时我们可以采用一些工具,比如,南极星,AppLocale 等,暂时的模拟不同的语言环境。
5.2 网页提交字符串
当页面中的表单提交字符串时,首先把字符串按照当前页面的编码,转化成字节串。然后再将每个字节转化成 “%XX” 的格式提交到 Web 服务器。比如,一个编码为 GB2312 的页面,提交 “中” 这个字符串时,提交给服务器的内容为 “%D6%D0”。在服务器端,Web 服务器把收到的 “%D6%D0” 转化成 [0xD6, 0xD0] 两个字节,然后再根据 GB2312 编码规则得到 “中” 字。在 Tomcat 服务器中,request.getParameter() 得到乱码时,常常是因为前面提到的“误解一”造成的。默认情况下,当提交 “%D6%D0” 给 Tomcat 服务器时,request.getParameter() 将返回 [0x00D6, 0x00D0] 两个 UNICODE 字符,而不是返回一个 “中” 字符。因此,我们需要使用 bytes = string.getBytes(“iso-8859-1”) 得到原始的字节串,再用 string = new String(bytes, “GB2312”) 重新得到正确的字符串 “中”。
5.3 从数据库读取字符串
通过数据库客户端(比如 ODBC 或 JDBC)从数据库服务器中读取字符串时,客户端需要从服务器获知所使用的 ANSI 编码。当数据库服务器发送字节流给客户端时,客户端负责将字节流按照正确的编码转化成 UNICODE 字符串。如果从数据库读取字符串时得到乱码,而数据库中存放的数据又是正确的,那么往往还是因为前面提到的“误解一”造成的。解决的办法还是通过 string = new String( string.getBytes(“iso-8859-1”), “GB2312”) 的方法,重新得到原始的字节串,再重新使用正确的编码转化成字符串。
5.4 电子邮件中的字符串
当一段 Text 或者 HTML 通过电子邮件传送时,发送的内容首先通过一种指定的字符编码转化成“字节串”,然后再把“字节串”通过一种指定的传输编码(Content-Transfer-Encoding)进行转化得到另一串“字节串”。比如,打开一封电子邮件源代码,可以看到类似的内容:
Content-Type: text/plain;
charset="gb2312"
Content-Transfer-Encoding: base64
sbG+qcrQuqO17cf4yee74bGjz9W7 +b3wudzA7dbQ0MQNCg0KvPKzxqO6uqO17cnnsaPW0NDEDQoNCg==
最常用的 Content-Transfer-Encoding 有 Base64 和 Quoted-Printable 两种。在对二进制文件或者中文文本进行转化时,Base64 得到的“字节串”比 Quoted-Printable 更短。在对英文文本进行转化时,Quoted-Printable 得到的“字节串”比 Base64 更短。
邮件的标题,用了一种更简短的格式来标注“字符编码”和“传输编码”。比如,标题内容为 “中”,则在邮件源代码中表示为:
// 正确的标题格式
Subject: =?GB2312?B?1tA=?=
其中,
- 第一个“=?”与“?”中间的部分指定了字符编码,在这个例子中指定的是 GB2312。
- “?”与“?”中间的“B”代表 Base64。如果是“Q”则代表 Quoted-Printable。
- 最后“?”与“?=”之间的部分,就是经过 GB2312 转化成字节串,再经过 Base64 转化后的标题内容。
如果“传输编码”改为 Quoted-Printable,同样,如果标题内容为 “中”:
// 正确的标题格式
Subject: =?GB2312?Q?=D6=D0?=
如果阅读邮件时出现乱码,一般是因为“字符编码”或“传输编码”指定有误,或者是没有指定。比如,有的发邮件组件在发送邮件时,标题 “中”:
// 错误的标题格式
Subject: =?ISO-8859-1?Q?=D6=D0?=
这样的表示,实际上是明确指明了标题为 [0x00D6, 0x00D0],即 “ÖД,而不是 “中”。